Introduction to Reproducible Coding Environment
Welcome
Today we’ll chat about reproducible coding environments in R. We’ll cover what reproducibility means, why it matters, and look at practical ways to make your research and data analysis easier to repeat and share.
About Code Club
SORTEE Code Club is an online meeting where people come together to learn, share, and collaborate on coding-related topics in an informal and supportive environment
SORTEE Resources
Do you know about SORTEE Resources ?
Today’s Agenda
What reproducibility actually means
Why reproducibility matters
Using R Projects
Managing package dependencies with renv
Handling different R versions
Some limitations and tips
Disclaimer : today’s Code Club will focus on Reproducibility in R
Introduction to Reproducibility in R
A reproducible coding environment is a computational setup with clearly documented code, data, software versions, and methods allowing exact replication of results.
Original comic from xkcd
The Why
Reproducible coding environments:
Ensure reliability and credibility of research findings
Facilitate collaborative research and transparent scientific communication
Enable efficient troubleshooting and debugging
Save time by reducing redundant efforts to recreate computational setups
Promote best practices in scientific computing and data analysis
So, why are we talking about reproducible coding environments? Why is a reproducible coding environment important?
The How
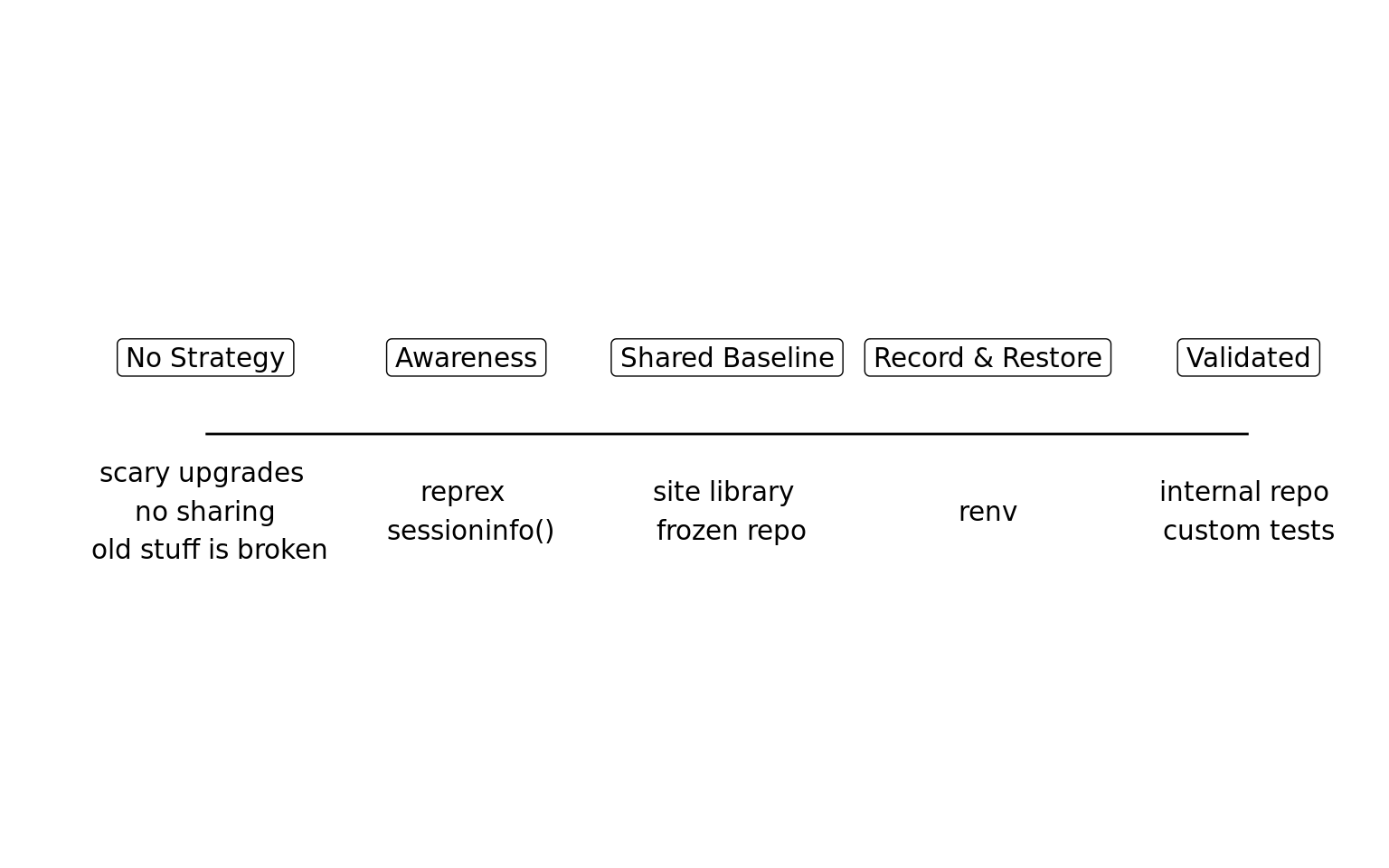
There is no single solution or perfect approach to reproducibility various best strategies that you can use!
Example
For example, consider different ways of referencing file paths in your R scripts:
# Bad: absolute path setwd ("C:/Users/MyName/Documents/Project/Data" )<- read.csv ("data.csv" )# OK: relative path extensively documented in README (but fragile!) setwd ("~/Downloads/Data" )<- read.csv ("data.csv" )# Better: using here package, but without RProject the structure is unclear library (here)<- read.csv (here ("Data" , "data.csv" ))# Best: explicit use of an R project (.Rproj file) ensures 'here()' always resolves correctly library (here)<- read.csv (here ("Data" , "data.csv" ))
It’s important to begin implementing reproducible practices incrementally, building up complexity and robustness over time rather than aiming for perfection from the start.
The How: .RProject
R Projects is a way to organize all your analysis files into one easy-to-use place.
R Projects make your life easier because:
Paths are simple(r)
Easy collaboration
Less confusion
How to make an .RProject
Example : .RProject
For example:
R Projects is one of the simplest and most effective ways to quickly become more reproducible. When you create an R Project, you get a special .Rproj file that marks the project’s root directory, meaning everything you do in that project stays nicely contained. - Paths are simple(r): You don’t have to worry about absolute paths that break when you move your files. Every file path you use is relative to your project, so it’s easy to share and move around without things breaking. - Easy collaboration: Because all your project’s files are in one clear place, anyone who receives your project can easily set it up on their computer and run your code exactly as you intended. - Less confusion: No more wondering where files are stored or which files belong to your analysis. Everything related to your project stays together and is clearly structured.
.RProject is not enough alone
Even though an R Project helps organize your analysis into one coherent location…
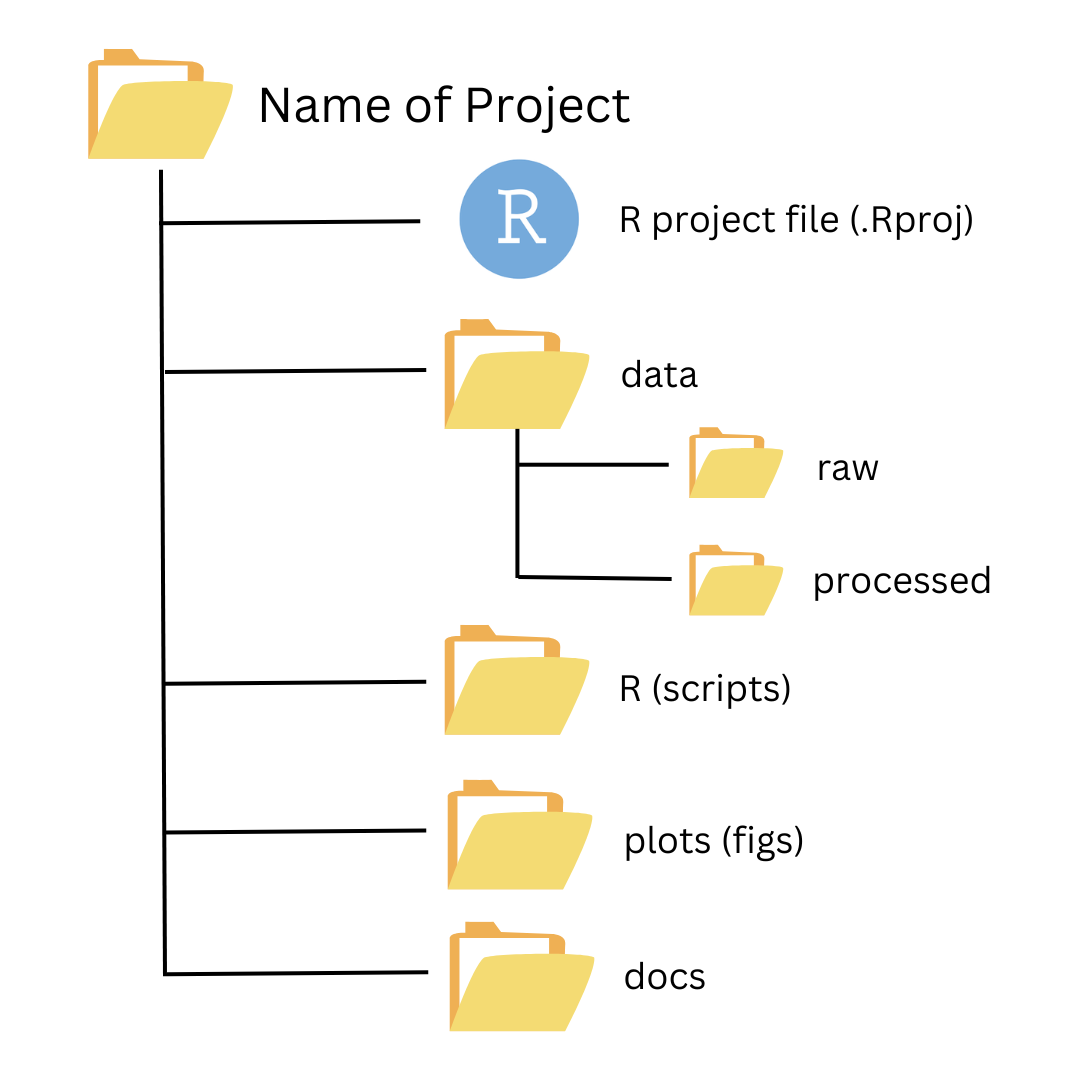
… You still need a structured directory layout to organize your file inside this project to get the most out of it
Organise your Files!
Not this!
But this!
Having an R project is a good start, but you still need to organise your files in a meaningful way, you can’t just throw everything in the same cauldron.
Understanding Packages📦 and Libraries📘
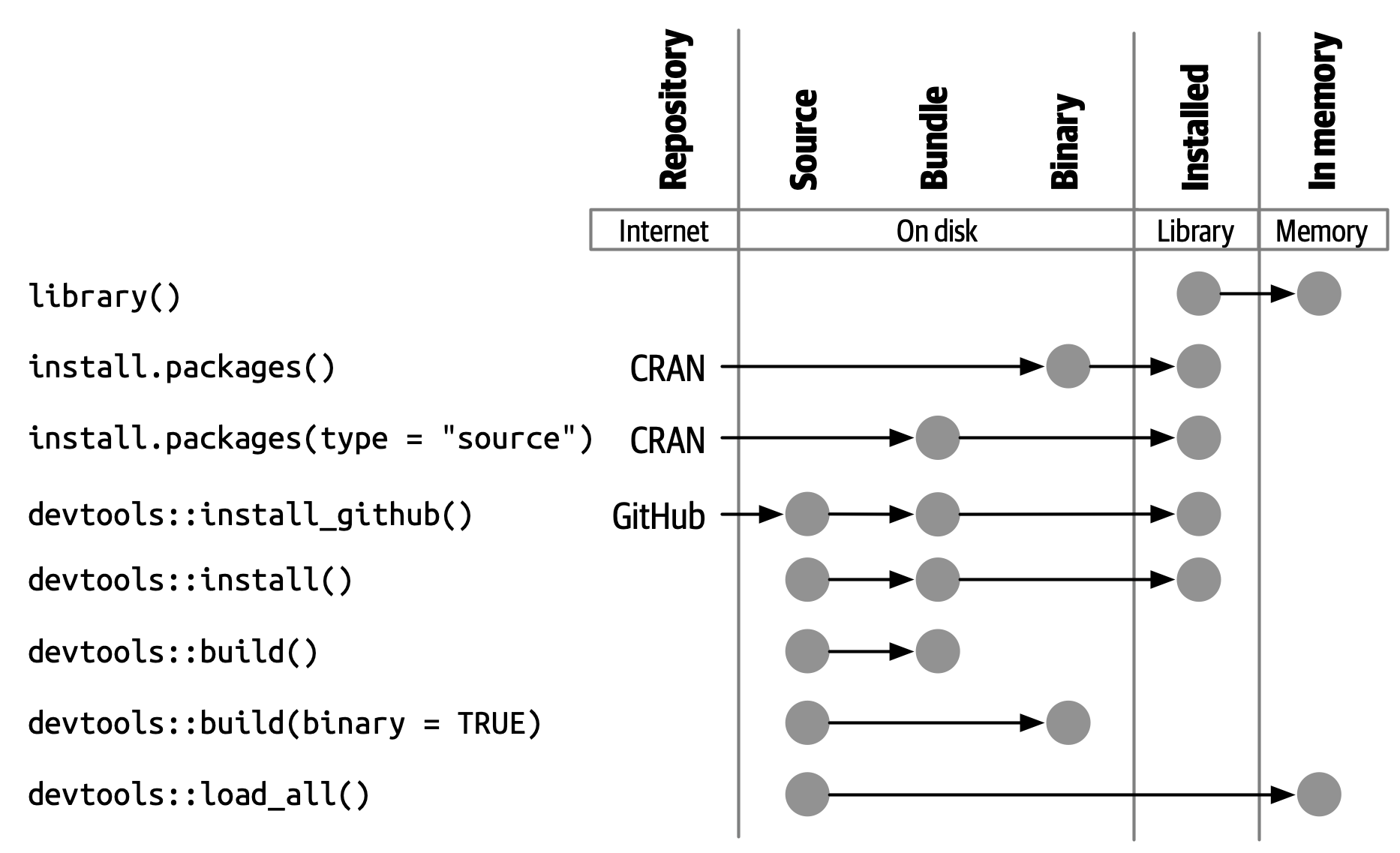
Collections of functions and compiled code that extend R’s functionality
Packages📦 reside within a library📘 , a directory on your computer where R stores installed packages
Managing package versions matters for:
Version control Transparency Open projects
The How: Managing Packages with renv
renv helps make your R projects reproducible by managing your package dependencies
It records which packages (and their versions) you’re using in your project.
It helps you avoid package version conflicts across different projects.
It ensures that your project setup can be easily replicated later.
renv stands for “R environment,” and it’s a package designed to keep your R project’s packages consistent and reproducible. Think of it like taking a “snapshot” of exactly which R packages you’re using in your project, including their exact versions.
Why does this matter? Because packages in R are constantly being updated, and sometimes updates change the way packages behave. Without controlling package versions, your code might run perfectly today but fail or give different results a few months down the line.
Using renv: you, starting the project
renv::init(): create an isolated library for your projectrenv::snapshot(): save exact versions of packages you’re using into a renv.lock file
This lockfile acts like a recipe that describes the environment your project needs to run.
When you’re working on a new project and want to make it reproducible, here’s what you do: - renv::init() — this creates a private library just for your project. That means any packages you install won’t interfere with other projects. - As you install packages and write code, use renv::snapshot() to save the current state of your project’s library. This creates a file called renv.lock, which records exactly which packages you’re using, their versions, and where they came from.
Using renv: someone else, with your project
Let’s say someone else wants to run your code. They don’t need to guess what packages or versions you used — they just run:
The command renv::restore() reads your renv.lock file and automatically installs all the required packages in the correct versions. It recreates the same package setup you used.
renv greatly simplifies reproducing the exact environment and package setup used in your project
Limitations
renv doesn’t handle:
R itself (versions)
System dependencies (compilers, external libraries)
However, no single tool handles everything. One of the limitations most R users forget abut renv is that renv does not handle R versions. So you could have a perfectly documented, saved project, but it might break because over time a new R version has been implemented. So you need complementary tools.
Managing R Versions
Sometimes it’s not just about the packages — the version of R itself can matter too.
That’s where Rig comes in.
Small changes between versions of R can affect how packages behave or whether certain functions are even available.
What is Rig?
Rig is a lightweight tool that helps you manage multiple versions of R on the same machine.
It works on Windows, macOS, and Linux .
You can easily install new R versions.
You can switch between R versions with a simple command.
Why Use Rig?
Makes it easy to test code across R versions.
Simplifies keeping old projects running on older setups.
Plays well with tools like renv, completing the reproducibility setup.
🧩 renv manages your packages
rig supports long-term reproducibility. If someone opens your project years later, they can install the same version of R and restore your setup.
Wrapping Up
Improving reproducibility:
Organize projects clearly
Manage dependencies carefully (renv)
Use version management (Rig)
Document everything!